오늘은 월별 황사 발생 일수를 파이썬을 이용해 그려보고자 합니다. 데이터도 간단하고, 그래프도 어렵지 않기 때문에 지난 코드에 비해 비교적 쉽게 접근 할 수 있을 것 같다는 생각이 드네요.
우선 데이터는 기상자료개방포털에서 다운로드 합시다. 구글에서 기상자료 개방포털를 검색하여 접속하여도 되고 아래 링크로 따라 들어가셔도 됩니다.
기상자료개방포털
날씨! 데이터가 되다 OPEN API
data.kma.go.kr
기상자료 개방포털의 맨 첫화면에서 기후통계분석 -> 황사일수로 차례로 클릭하시면 됩니다.
그럼 아래와 같은 화면이 나오는데, 자료 구분은 월로 그대로 두시고, 지역/지점 아래의 서울이라고 써 있는 곳을 클릭하면 원하는 지역을 선택할 수 있습니다. 저의 경우 원주로 클릭하였습니다. 기간은 너무 과거로 돌아가면 중간중간 빈 데이터가 있기 때문에 적당히 1970년대 정도로 하시는게 좋습니다. 빈 데이터가 있으면, 이 아이들은 무시하고 기록할 수 있지만, 오늘은 간단한 코드로 해 볼 예정이기에 우선 완전한 데이터를 만들어 보려 합니다.

이렇게 한 뒤 중간 쯤에 보이는 csv를 클릭하면, csv 데이터가 다운로드 됩니다.
다운로드한 csv를 엑셀을 이용해서 열면 우리에게 불필요한 정보도 있고, 한글로 되어있는 정보도 있어 조금 가공을 해 줍시다.

맨 윗줄의 빈 행은 당연히 삭제하고, 첫 번째 행 부터 평균 황사일수까지의 행을 모조리 삭제해 줍시다.
그리고 연도 아래에 평년, 최근 10년에 해당하는 행도 삭제해 줍시다.
그 다음에 연도, 1월,2월~12월의 글자는 영어와 숫자로 바꾸어 줍시다.
연 합계와 순위 역시 필요없습니다. 해당 열 역시 모조리 삭제
다음으로 스크롤을 조금 내리면

요런 아이들이 보입니다. 모조리 삭제해 줍시다.
그렇게 데이터를 좀 가공하여서

이렇게 필요한 값만 추출하였습니다. 파이썬에서 이 작업이 가능하기는 하지만, 엑셀에서 하는것이 훨씬 직관적이고, 이건 어디까지나 실습용 데이터를 만드는 과정이니 크게 의미를 두지는 않겠습니다.
이렇게 하면 year부터 12까지의 총 13개의 열이 생겼고, 1972년부터 2022년까지 엄청 많은 양의 행이 생겼습니다.
1. 월별 황사 발생일수 계산하기
첫 번째로 월별 황사 발생일수를 계산해 보고 이것을 막대그래프 형식으로 만들어 보겠습니다.
1972~2022년까지 원주에서 발생한 황사를 월별로 계산해야하니, 1월에 해당하는 모든 값을 다 더하고, 2월, 3월~12월까지 마찬가지 작업을 해야 합니다.
import numpy as np ## numpy 호출
import pandas as pd ## pandas 호출
import matplotlib.pyplot as plt ## matplotlib 호출
data=pd.read_csv("C:\\111\\wonjudust.csv") ## csv 데이터 불러오기
m=np.arange(1,13,1) ## 1,12까지의 수를 1간격으로 불러오는 1차원 행렬 만들기
result=[] ## 계산 결과를 저장할 빈 리스트 만들기
for x in m:
rest=data[str(x)].sum() #변수 m에 지정한 숫자를 1부터 12까지 차례로 집어넣고 해당 열 모두 합
result.append(rest) ## 계산 결과를 차곡차곡 result라는 변수에 저장
print(result) ##제대로 출력 되는지 확인
plt.xticks(m) ## x축값 간격 지정
plt.xlabel('month') ##x축 이름
plt.ylabel('year') ##y축 이름
plt.title('Number of dust storm days per month') ## 그래프 제목
plt.bar(m,result,color='pink') ## 그래프 그리기
plt.savefig("C:\\111\\wonjudust.jpg",dpi=300) ## 그래프 저장
plt.show()코드에 대한 설명은 주석으로 모두 달았습니다. 여기서 주의할것은 data[str(x)].sum() 입니다.
for문에서 받는 반복 숫자 x는 arange로 받았기 때문에 모두 숫자입니다. 하지만, 해당 열의 이름 1,2,3,4,5~12는 모두 문자입니다. 값이 아닙니다. 때문에 문자로 취급해 주기 위하여 str을 사용하였습니다. 나머지는 모두 간단한 것이기 때문에 쉽게 이해할 수 있으리라 생각합니다. 이렇게 해서 그래프를 출력하면

원주의 값만 하기 좀 그러니 서울과 함께 비교해 보겠습니다. 코드는 간단합니다. 위 원주의 값에 대하여 서울만 추가하면 됩니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_csv("C:\\111\\wonjudust.csv")
data2=pd.read_csv("C:\\111\\seouldust2.csv")
m=np.arange(1,13,1)
wonju=[]
seoul=[]
for x in m:
rest=data[str(x)].sum()
wonju.append(rest)
for y in m:
rest2=data2[str(y)].sum()
seoul.append(rest2)
print(wonju)
print(seoul)
plt.xticks(m)
plt.xlabel('month')
plt.ylabel('year')
plt.title('Number of dust storm days per month')
plt.bar(m,seoul, label='Seoul')
plt.bar(m,wonju, label='Wonju')
plt.legend()
plt.savefig("C:\\111\\wonjuseouldust.jpg",dpi=300)
plt.show()마찬가지로 해당 열의 값을 모두 더하는 data2[str(y)].sum() 만 주의하면 됩니다. 나머지는 모두 그동안 하던 것 들입니다.
이렇게 해서 그린 결과는

2. 년도별 황사 발생일수 계산하기
이번에는 년도별로 황사발생일이 어떻게 변했는지 그려보겠습니다. 먼저 데이터의 구조를 보면
위 그림처럼 열은 월별 황사 발생일수이고, 행은 년도별 황사발생일수임을 알 수 있습니다. 년도별로 황사발생일수를 알려면 해당년도에 발생한 월별 황사 발생일수를 모두 더해야 합니다. 예를들어 1976년의 경우 3월에 2회, 4월에 2회, 5월에 4회, 12월에 1회의 황사가 발생하였다고 기록되었습니다. 이를 모두 더하면 1976년에 발생한 황사 발생 일수가 될 겁니다. 그럼 1976년에는 총 9회의 황사가 발생한 것이 됩니다. 따라서 코드는 행 방향의 데이터를 모두 더하도록 짜야합니다.
새로 방향, 그러니까 열 방향으로 데이터를 더하는것은 data[str(1)].sum()으로 간단하게 해결하였습니다. 행 방향도 어렵지 않습니다. 기본적으로 sum()라고 하고 () 사이에 아무것도 입력하지 않으면 axis=0이 생략된 상태라고 생각하시면 됩니다. 이는 열 방향으로, 다시말해 세로로 더하라는 의미입니다.
만약 ()에 axis=1 또는 axis='columns'라고 입력하면 이 때는 행 방향, 다시말해 가로 방향으로 계산하라는 의미가 됩니다.
따라서 data.sum(axis=1)이라고 입력하면 행방향으로 더하는데 문제는 가장 왼쪽 열의 년도까지 모두 더해버립니다. 년도는 더하면 안되겠죠? 그러니 잠시 년도는 지워주고, 이를 새로운 데이터 변수로 지정해 줍시다. 해당 열을 모두 지우는 방법은 간단합니다. drop를 사용하는 건데, 아래 코드를 참고하세요
data2=data.drop('year',axis=1)
이렇게 쓰면 data라는 변수에 있는 csv 파일에서 'year'이라는 열을 세로 방향으로, 그러니까 열 방향으로는 모두 지우라는 소리가 됩니다.
이렇게 지운 데이터를 data2라는 변수에 새롭게 집어넣었습니다.
이제 전체 코드를 보면
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_csv("C:\\111\\wonjudust.csv")
data2=data.drop('year',axis=1) ## 해당 열 삭제
x=data['year']
y=data2.sum(axis=1) ## 행 방향으로 데이터 더하기
plt.plot(x,y,label='Wonju')
plt.grid(ls='--')
plt.savefig("C:\\111\\wonjuseouldustday.jpg",dpi=300)
plt.show()이렇게 하여 나온 결과는 아래와 같습니다.

년도에 따른 특별한 변화 경향은 없으나, 주목할 만한것은 2000년도 초반에 한번 말도 안되게 뻥 뛴적이 있습니다. 이게 원주만의 경향인지 다른 도시에서도 동일하게 나타났는지, 그리고 서울과 비교하였을 때 원주는 황사가 얼마나 발생했는지 확인할 필요가 있습니다. 그래서 서울과 비교했습니다. 코드는 위와 같습니다. 서울만 추가해주면 되요. 결과는 아래와 같습니다.
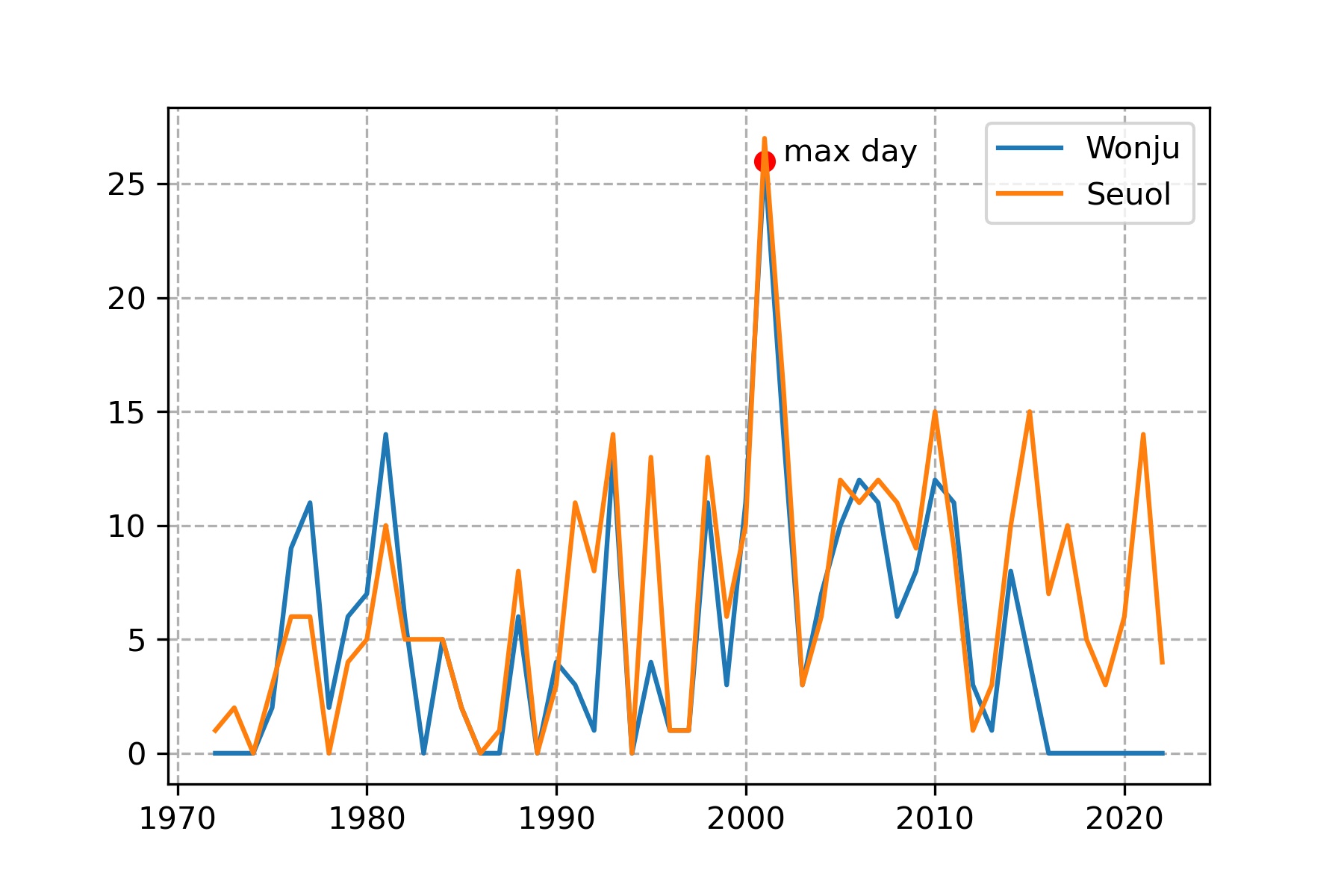
서울과 비교하였을 때에도 마찬가지 결과가 나타났습니다. 년도가 언제인지 구체적으로 알아보니 2001년도였습니다. 계산 결과의 최대값이 몇 년도인지 알려면
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_csv("C:\\111\\wonjudust.csv")
data2=data.drop('year',axis=1)
x=data['year']
y=data2.sum(axis=1)
data.insert(13,'total',y)
print(data.loc[data['total'].idxmax()])여기서 중요한 코드는
1. print(data.loc[data['total'].idxmax()])
2. data.insert(13,'total',y)
입니다. 2번에 있는 코드는, 앞서 월별로 모두 더한 황사 발생일수의 계산 결과를 맨 마지막 열에 추가하기 위해 써 넣은 코드입니다. insert라는 함수를 사용했구요, 13은 14번째 열에 추가하라는 의미, 'total'은 해당 열의 이름, y는 추가할 데이터입니다.
1번에 있는 코드는 이제 total이라는 열에서 최대치를 나타내는 행을 모두 토해내라 라는 의미입니다. 이렇게 코드를 입력하면 아래와 같은 결론이 나옵니다.

해당 년도가 2001년이고, 이때 total값은 26이라는 것을 알 수 있습니다.
2001년에 갑자기 뻥 뛴것이 원주와 서울에서 확인되었습니다. 다른지역은 어땠는지 궁금하여 제가 하지않고(ㅋㅋㅋ)학생들에게 과제로 내 주었습니다. 결과는 아래와 같습니다.

원주, 서울, 강릉 모두 2001년도에 황사 발생일수가 월등히 높습니다. 이 때 무슨 이벤트가 있는지 확인해 볼 필요가 있을 것 같습니다.
기상자료 개방포털에는 통계자료를 만들만한 데이터가 참 많습니다. 다음번에는 폭염일수 변화를 지역별로 알아보는 코드를 만들어 보겠습니다.
'파이썬으로 배우는 지구과학' 카테고리의 다른 글
| 파이썬을 이용하여 허셜 우주망원경의 적외선 관측 데이터 분석하기 (4) | 2022.09.02 |
|---|---|
| 파이썬을 이용하여 위도별 만유인력, 원심력, 표준중력 변화 그래프 그리기 (0) | 2022.08.24 |
| 파이썬을 이용하여 타원 방정식 그래프 그리기 (0) | 2022.07.02 |
| 파이썬을 이용하여 위도별 지구 반지름 계산하기 (0) | 2022.06.27 |
| 파이썬을 이용한 바람장미 그리기 두 번째 (0) | 2022.06.17 |




댓글